

Vector databases have been around for decades. But with the Gen AI revolution, their value is now in the spotlight more than ever. The topic is fueling boardroom and conference discussions across industries. According to Gartner, by 2026, more than 30% of enterprises will have adopted vector databases to enrich their foundation models with relevant business data.
And it comes as no surprise, as vector databases help address critical challenges posed by Generative AI applications, which often deal with massive volumes of unstructured data, operate in high-dimensional spaces, and require searching for similarities.
Vector databases help significantly increase the accuracy, responsiveness, and scalability of AI models. But like any technology, especially one surrounded by hype, you’ll only get real business results if you fit it to the right use cases and let value, not trends, guide you.
So, how do vector databases work? How can enterprises benefit from them? Is your use case well-suited for a vector database, or are alternatives a better fit? And most importantly, how can you integrate one into your enterprise data and analytics ecosystem while avoiding risks and guesswork?
Let’s discover the answers together with our Data and AI Competence Service Lead, Viacheslav Brui.
What is a vector database?
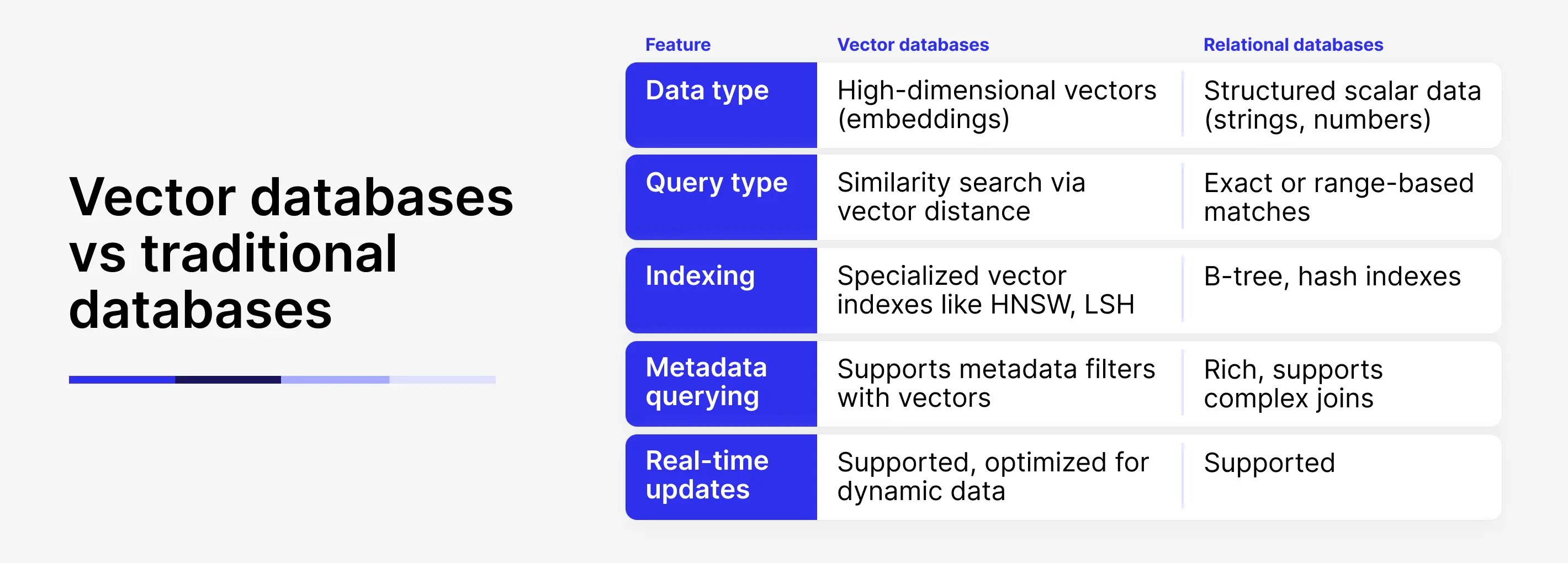
A vector database is a system that stores and searches information based on meaning and similarity, rather than exact matches.
Instead of traditional rows and columns, vector databases store numerical embeddings representing text, images, video, or audio. When an AI model queries the database, it converts the query into a vector. The database then finds the most similar embeddings, enabling contextually relevant, real-time responses.
In plain terms: a vector database lets AI understand your data, not just read it literally. This is essential for generative AI, which needs to access dynamic, unstructured datasets efficiently.
Why vector databases matter in the era of generative AI
LLMs are powerful but limited by context windows: they cannot process all private or rapidly changing data in one prompt. Enterprises face a choice:
- Fine-tuning LLMs: improves relevance but is costly, slow, and risky for volatile data.
- RAG (Retrieval-Augmented Generation): fetches only the most relevant data from a vector database for real-time AI responses.
- CAG (Cache-Augmented Generation): loads all relevant context into a large model’s extended context window and caches its runtime parameters.
Vector databases make RAG possible, enabling AI systems to retrieve context-aware data instantly, without retraining or overspending.
Why traditional databases fall short
Traditional databases were built to handle structured data and exact matches, not semantic similarity across complex, unstructured data. They can’t efficiently search millions of high-dimensional vectors or deliver context-aware results in real time.
Vector databases solve this problem, unlocking fast, accurate, and scalable knowledge retrieval, which is exactly what today’s Gen AI systems need.
How your enterprise can benefit from vector databases in AI

Turning unstructured data into business insights
According to IBM, the volumes of unstructured data (text, audio, images, video, etc.) are growing 30% to 60% year over year. Vector databases are designed to translate these massive, high-dimensional datasets into vector embeddings, which allows applying them to AI/ML scenarios and turning them into actionable insights.
Enhanced scalability and speed of data management
Vector databases combine quick similarity search with low latency and high throughput, even at a scale of millions to billions of data points.
What’s more, the databases support horizontal scaling and allow adding nodes to your infrastructure, so your solution doesn’t hit scalability bottlenecks when you deal with increasingly growing datasets and query loads.
Avoiding the “LLM fine-tuning” costs and complexity
While feeding new data into an already powerful model might be a logical thing to do to improve performance. However, adding new data to an advanced LLM means overwriting existing knowledge, which increases the risk of losing the initial information.
As previously mentioned, vector databases are crucial for Retrieval-Augmented Generation (RAG). This approach allows the use of internal data for large language models (LLMs) and generative AI without requiring fine-tuning, resulting in more relevant responses and minimizing hallucinations, all while avoiding overhead.
Improved personalization and customer engagement
They often power highly personalized recommendations, chatbots, and virtual assistants. If you want to enhance user experience and improve customer retention, a vector database could be a valuable option.
Reduced infrastructure costs when dealing with large, unstructured datasets
Vector databases optimize storage and computing resources by using advanced methods of indexing, compression, and tiered data management. If your business handles large amounts of unstructured data, vector databases can significantly lower your storage and management costs.
Native compatibility with AI/ML pipelines
These databases natively manage embeddings generated by models like BERT, GPT, or others. That helps facilitate and speed up data transformation and deployment.
Support for complex and hybrid queries
Besides pure vector similarity, many vector databases allow combining vector search with metadata filtering or keyword search. This helps improve relevance and flexibility in many AI applications (e.g., multimodal search or RAG).
Top use cases for vector databases
Though Gen AI is now a buzzword on everyone’s lips, it represents just a part of the broader data, analytics, and AI/ML use cases. The applications of vector-based databases offer a wide range of benefits across various use cases such as recommendation systems, anomaly detection, retrieval-augmented generation (RAG), and more.
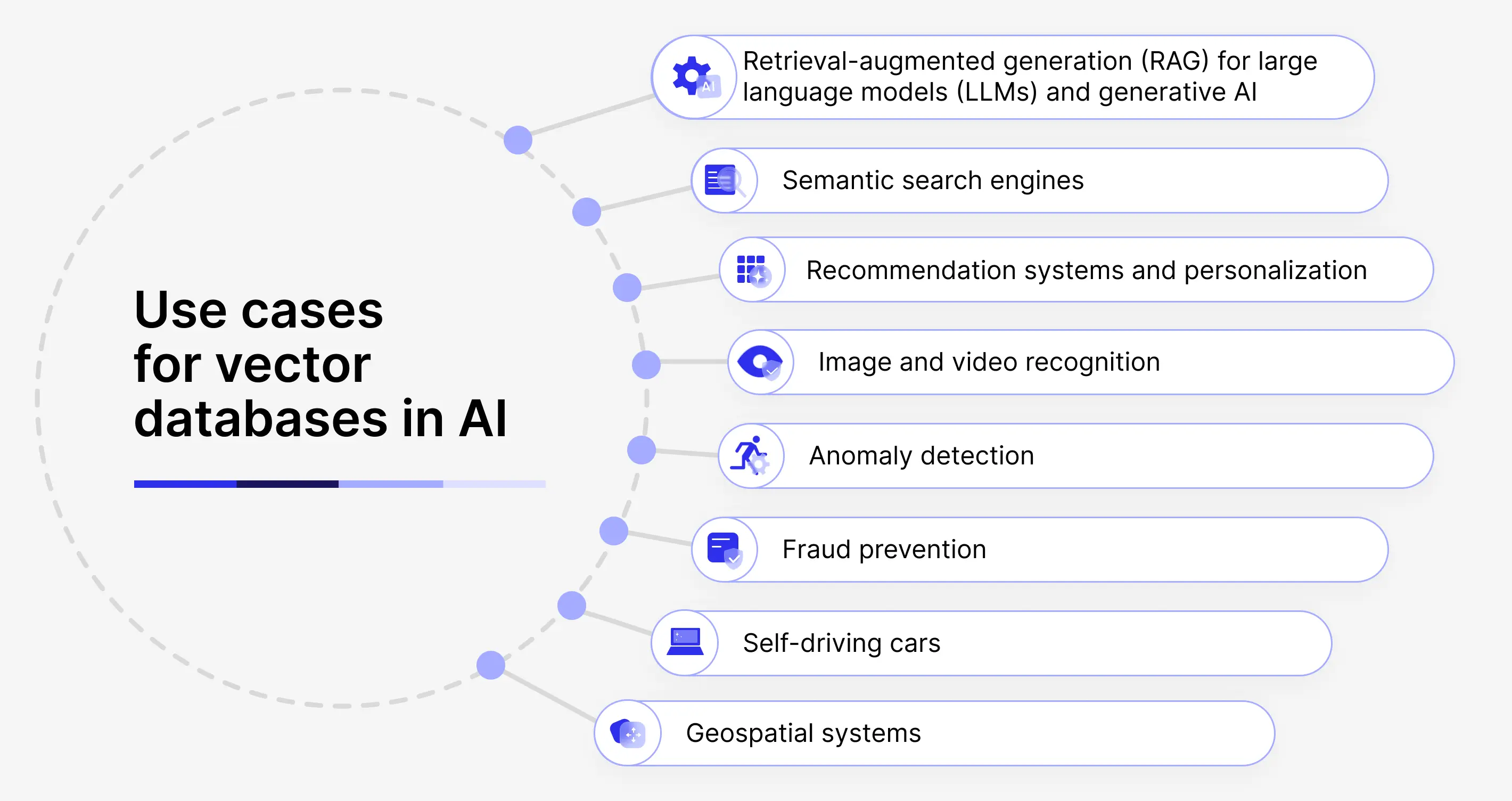
Retrieval-augmented generation (RAG)
LLMs cannot access private, dynamic enterprise data unless retrained. Fine-tuning is expensive and impractical for volatile datasets. RAG, powered by a vector database, allows AI to:
- Retrieve only relevant data in real-time.
- Ground responses in actual internal knowledge.
- Reduce hallucinations and minimize fine-tuning costs.
Impact: More accurate answers, faster responses, and lower AI operating costs.
Semantic search
Move beyond keyword matching, vector databases understand intent and context, enabling complex, natural-language queries across multiple systems.
Recommendation systems
Vector embeddings allow real-time, personalized recommendations for users and items. Ideal for e-commerce, media streaming, or any service requiring dynamic personalization at scale. For example, the integration of Vector Databases has transformed how content is suggested to users on Netflix, Spotify, and Amazon. The ability to quickly identify items similar to what a user enjoys ensures a seamless and engaging experience.
Image and video recognition
Scale multimedia analysis efficiently. Useful in e-commerce, security, media platforms, or social networks for similarity search and automated tagging.
Other applications
Fraud detection, anomaly detection, geospatial analysis, IoT monitoring, and any AI workflow that requires high-dimensional similarity search.
Technical deep dive: how vector databases work
Vector databases store embeddings and use Approximate Nearest Neighbor (ANN) algorithms like:
- HNSW (Hierarchical Navigable Small World)
- LSH (Locality-Sensitive Hashing)
- PQ (Product Quantization)
These techniques allow databases to retrieve similar vectors quickly, even in billions of records, without scanning the entire dataset.

*Hybrid search allows you to search vector fields and apply relational database filters. Native vector databases don’t support these filters.
Three options for vector search in high-dimensional data
When you need vector search for your high-dimensional data, there are primarily 3 options:
- Native vector databases (e.g., Qdrant, Pinecone, Milvus, Weaviate, Chroma) are specialized systems built solely for vector search workloads, optimized for ultra-fast approximate nearest neighbor searches on large-scale vector embeddings. Their architecture is specifically designed for unstructured vector data, providing faster searches and improved scalability compared to general-purpose systems. However, they may lack features like relational data management, support for row-level security, complex transactions, or integrated storage for structured data.
- Multimodal databases (e.g., PostgreSQL with pgvector, Redis with vector modules) are traditional databases extended with vector search capabilities, allowing for both structured data management and vector search. They can be a pragmatic choice for smaller-scale or hybrid use cases, especially when compliance and security are paramount.
- Multimodal data platforms (e.g., Snowflake, Databricks) are comprehensive enterprise platforms that combine vector search with advanced data processing, AI/ML pipelines, governance, and analytics, supporting seamless work across multiple data types and AI use cases.
Each option fits different workload requirements, scale, operational complexity, and integration preferences. Native vector databases are a good choice when vector search is central and scalability at very low latency matters. Multimodal databases and platforms support broader enterprise needs that combine vector data with relational or other structured datasets.
When implementing vector search, two main types of databases are commonly used: native vector databases and multimodal (or vector-enabled) databases. Understanding their strengths will help you choose the right one for your use case.
Which database to choose for your enterprise?
Native vector databases
Native vector databases are purpose-built for vector search and optimized for ultra-fast, high-throughput similarity queries at scale. They are ideal when vector search is the core operation of your application, such as:
- Large-scale semantic search and document retrieval
- Real-time recommendation engines powered by user and item embeddings
- Image, audio, or video similarity search in multimedia applications
- Anomaly detection in high-dimensional sensor or behavioral data
- Complex AI workflows that heavily rely on vector search performance
Limitations: Native vector databases generally focus only on vector fields and do not support traditional relational filtering or hybrid search. This means you can’t easily apply attribute-based filters (e.g., “find similar images uploaded last week by user X”) alongside vector similarity search.
Multimodal (vector-enabled) databases
Multimodal databases extend traditional relational or key-value databases (like PostgreSQL or Redis) with vector search capabilities.
They are the best fit when you need to combine structured and unstructured data in the same workflows. Multimodal databases support hybrid search—allowing you to search vector fields and apply relational filters at the same time. This flexibility makes them more practical for many production business applications. They are especially useful when:
- You must work with both structured (e.g., customer profiles) and unstructured (e.g., text embeddings or image vectors) data together
- You need row-level security (RLS) and must meet strict compliance, governance, or auditing requirements
- You require transactional integrity and complex transactional support alongside vector similarity search
- Your vector data volumes are small to moderate, and ultra-fast performance is not a priority
- You want to leverage existing relational infrastructure and add vector capabilities without deploying an entirely new system

For instance, here is how we helped our client build a more efficient and user-friendly search system by using a multimodal vector-based database (PostgreSQL with the pgvector extension).
Success story: Using a multimodal vector database to enhance complex search and user experience in construction and geoinformation systems
Customer background:
Our client is involved in the construction industry and geoinformation systems. Their platform offers real-time insights into the condition of engineering networks throughout a city. It monitors key events such as recent incidents, scheduled maintenance, and service requests, detailing when, where, and how these occurred. It also tracks construction permits, providing information on the current stage of development for ongoing projects.
Business challenge:
The client already had a search system in place, but it was highly complex and difficult to use. To retrieve meaningful results, users had to input precise combinations of logical conditions. The process was not user-friendly and led to a poor user experience. The underlying data structures and APIs were complex, making querying cumbersome and inefficient.
Solution:
We developed an AI search designed to allow users find information using natural language.
Given the complexity of the target search system, RAG was selected as one of the key techniques for context engineering. We chose PostgreSQL with pgvector because it offered the best balance of cost-efficiency and production-grade performance for our client’s specific case.
The system uses RAG in two distinct steps:
- It searches the documentation to retrieve the most relevant pieces that provide context for the AI agent’s responses.
- It performs a similarity search to find valid, relevant past query examples from the knowledge base, which the LLM uses as references to improve accuracy.
Value delivered:
- Significantly improved user experience: The chatbot simplifies complex searches that previously required manual query construction.
- Unified data access: This solution seamlessly combines data from multiple sources. In the past, users needed to manually integrate various searches and datasets to conclude
- Higher accuracy and relevance: Leveraging similarity search and RAG techniques helps ensure that responses are grounded in verified examples and correct documentation. Additionally, RAG allows for obtaining the expected AI agent knowledge base relatively easily.
To achieve the best cost-value ratio, it is essential to choose the right database from among a myriad of solutions that best fits the client’s business context, needs, and technology infrastructure.
How to select the database that will be the best fit for a specific use case and business need
There are no universal solutions, and when choosing a specific database that will be the best fit for maximum performance and cost-efficiency, our team evaluates each case in detail, taking into account such key factors as:
- Stability: Will the system deliver consistent, reliable results on your current and evolving data size and complexity?
- Data volume and specifics: How large and complex is your dataset? Is it going to increase? Can the database handle your industry-specific data types?
- Compliance and security requirements: Does the database support enterprise-grade security features such as:
- Row-level security
- Encryption at rest and in transit
- Audit logging and monitoring
- Fine-grained access control and governance policies
- Pricing: Is the cost of ownership worth the results?
- Avoiding vendor-lock-in: In many cases, cloud-agnostic solutions will be better than cloud-native ones.
- Infrastructure complexity: From an engineering view, managing fewer services reduces complexity. But your final choice must match your actual business and technical needs, not just ease of deployment.
- Integration compatibility: Ensure it integrates smoothly with your existing data lakes, databases, ML tools, and APIs.
To ensure both quick wins and long-term gains, when working with vector-based databases, our team follows such time-tested best practices:
- Involving stakeholders early and making sure everyone is on the same page
- Ensuring security, governance, and compliance
- Architecting for scalability, high availability, and flexibility
- Applying a phased, modular approach
- Planning for smooth integration into the existing infrastructure
- Optimizing indexing and querying to achieve the best level of speed, performance, and cost-efficiency

Conclusion
Enterprises are investing heavily in AI, yet many see disappointing results:
- Millions spent fine-tuning LLMs that still hallucinate
- Poor search experiences because traditional databases can’t handle unstructured data
- Compliance and governance headaches when knowledge isn’t retrieved correctly
AI investments will only pay off with the right data foundation. Without a system that retrieves relevant, context-aware knowledge, even the most advanced AI models fail to deliver measurable business value.
Vector databases are no longer a niche technology—they are foundational for enterprise AI and generative AI success. They enable:
- Accurate, context-aware AI responses
- Real-time personalization and recommendations
- Scalable analysis of unstructured data
- Cost-efficient alternatives to extensive model fine-tuning
Choosing the right vendor who can assist in implementing the right type of vector database—native or multimodal—based on data, compliance, scale, and workload ensure enterprises maximize value while controlling costs.



