

Every large company is pursuing AI projects in one form or another. There are pilots. There are demos. There are vendor evaluations, internal hackathons, and executive decks full of use cases. What there almost never is, however, is a clear answer to who owns the decision to move an initiative into production, what it costs to run per unit of work, who is accountable when it breaks, and what evidence would justify stopping it.
The reason is straightforward. AI initiatives still lack a common, well-researched operating model – one comparable to those in finance, security, or product development. As a result, pilot after pilot dies in the space between “this demo looks great” and “this is how we work now.”
The numbers confirm it.
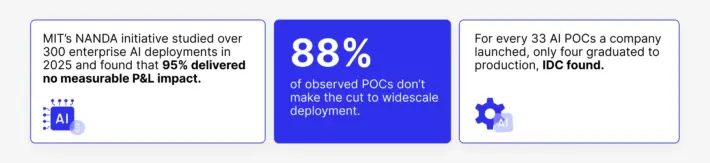
Sources: MIT’s NANDA study, ISC research.
Companies are failing because they never built the organizational system to make AI work past the demo stage.
As we explored in “AI: Expectations vs. Reality,” the disconnect between AI investment and AI results often begins with unclear goals, inadequate data readiness, and underestimated operational complexity.
This article explains what an AI operating model is, how to build one within real organizations, and the value of working with an experienced partner.
Most AI pilots fail not because of the models, but because there is no operating model around them. To move AI from demo to “how we work,” you need seven things: a clear unit of work, named decision owners, explicit data and risk boundaries, a funding model based on unit economics, written scale and stop criteria, and a regular operating cadence. Sombra’s AI Lab helps enterprises design and validate this operating model on real workflows before engineering begins.
What Is an AI Operating Model in Enterprise AI?
An AI operating model is the concrete system your organization uses to take an AI capability from idea to running production workflow, and then to keep it running, funded, monitored, and improving.
For example, when your finance team processes invoices, there is an operating model around that work: roles, approvals, controls, exception handling, audit trails, and cost allocation. Yes, nobody calls it an “operating model” in everyday conversation, but if you removed it, invoice processing would collapse into chaos within a week.
AI needs the same thing. Every AI system that touches a real workflow creates decisions that require owners, costs that necessitate budgets, risks that necessitate boundaries, and performance signals that require someone to pay attention. Without a system for handling all of that, each AI project reinvents the wheel, fights the same political battles, and discovers the same operational surprises.
At Sombra, we consider a working AI operating model to have seven components. Each one addresses a specific failure mode we see repeatedly in enterprise AI initiatives.
The 7 Components of a Working AI Operating Model
1. Unit of Work and Measurable Outcome
Every AI initiative should begin by identifying its unit of work — the discrete, quantifiable item the system will process. In an inspection workflow, this could be a single inspection package: photos, metadata, and a compliance checklist. In underwriting, it may be an application file. For a contact center, the unit could be a customer interaction. For document review, it might be a contract.
Once you have the unit, you can define outcomes in terms a CFO can audit: cost per unit, time per unit, error rate per unit, throughput per period. You can set a baseline, measure change, and calculate return. Without the unit, you are measuring feelings. With it, you are measuring operations.
This is where most AI initiatives go wrong first. The goal is stated as “improve efficiency” or “automate the review process.” Those are directions, not measurements. An operating model demands the measurement upfront because every downstream decision – budget, staffing, scaling, stopping – depends on it.
2. Decision Rights with Names Attached
AI changes how decisions get made inside a business. That means someone has to own those changes. Typically, a person with a name and a title can say yes, say stop, and be held accountable.
In an ideal world, we use four owner roles because they cover the territory where AI projects actually stall.
The business owner is accountable for the workflow outcome and the adoption plan. This is the person who cares whether the AI system actually changes how work gets done, not just whether it produces impressive outputs in a test environment. They own the question: is this making our operation better?
The data owner is accountable for what the system can access and what it cannot. Data permissions in AI are not a one-time setup. They involve ongoing decisions about retention, access scope, cross-system retrieval, and what happens when regulations change. Someone has to own that boundary.
The risk owner is accountable for the error boundary. Every AI system gets things wrong. The question is: how wrong, how often, and what happens when it does? The risk owner defines acceptable error rates, sets escalation policy, and has the authority to pause or restrict the system if it crosses a line.
The platform owner is accountable for keeping it running. Deployment, monitoring, evaluation, rollback, incident response, and the infrastructure that supports all of it. This is the person who knows what to do.
When these four roles are filled with real names at the start of an initiative, the project moves faster. Decisions do not pile up in steering committees. Design stays within the boundary that will actually get approved. And the first production incident does not become an existential crisis because there is already someone responsible for handling it.
When these roles are left vague, what happens is predictable: the pilot works fine in the lab, then stalls for months while the organization figures out who is allowed to say yes.
3. Data Boundaries
This is the part about what an AI system can touch, and what it cannot, and the rules for how.
This sounds like a security question, and it partly is. But the operating model concern is broader. Data boundaries define the inputs the system can use, the outputs it can produce, what gets stored, what gets logged, who can see what, and how long records are retained. They also define what happens when something changes – a new regulation, a new data source, a customer request to delete.
The reason this needs to be explicit is trust. Auditors need to know where evidence lives. Compliance teams need to know what crosses which boundary. Operators need to know what the system will never do, even if it technically could.
In a recent AI project with an LPG distributor, we encountered a core challenge: fragmented records. Drivers submitted field photos and videos, but there was no consistent method for storing, reviewing, or retrieving these records during audits. Drawing on our data and analytics expertise, we developed an AI system that established a unified, auditable data trail. Importantly, this data boundary was set by an operating model decision, not as a technical feature.
4. Risk Boundary and Escalation Design
Every AI system operating in a real business process will encounter uncertainty. The right question to ask here is: where does uncertainty go, what context travels with it, what is the human reviewer expected to do, and what gets recorded?
Escalation design is the connective tissue between the AI model and the human operation around it. As AI agents become common in enterprise workflows, getting the escalation design right becomes even more critical. A good escalation design lets the system route confident decisions quickly while sending uncertain ones to the right person with enough context to act. A bad escalation design – or no escalation design – means either the system gets overridden constantly and provides no value, or it runs unsupervised and eventually causes an incident.
In the safety inspection example, the escalation design was what made the throughput gains possible. The system could handle straightforward cases automatically, freeing human reviewers to focus on the cases that actually needed judgment. That split reduced manual review time by up to 80% and increased throughput by 1.5x. But the split only worked because someone had explicitly designed where the boundary sat, what happened at the boundary, and how the boundary would be adjusted over time.
5. Funding Model and Unit Economics
AI is an ongoing operation with ongoing costs. Inference costs, monitoring costs, evaluation upkeep, human review for escalations, incident response, and periodic retraining or adjustment as conditions change.
If your funding model treats AI like traditional software – a big upfront investment followed by low maintenance – you will consistently underinvest in the work that keeps AI systems reliable after launch. Teams will optimize for impressive demos because that is what gets funded.
A real funding model starts with unit economics. What does it cost to process one unit of work through this system, including the AI inference, the retrieval, the human review time for escalations, and the overhead? What is that cost relative to the manual baseline? What is the projected volume, and how do costs scale?
A rigorous funding model exposes reality. Some seemingly transformative AI projects collapse under poor unit economics, while seemingly modest ideas unlock massive returns through scale.
6. Scale Criteria and Stop Criteria
Scale criteria answer a specific question: what evidence does the organization need to see before widening usage?
Stop criteria answer the inverse: what conditions trigger a shutdown decision?
Both types of criteria need to be written down before the pilot begins, and each one needs a named owner who is responsible for evaluating the evidence and making the call. Without this, pilots become undead – never alive enough to scale, never dead enough to free up resources.
7. Operating Cadence and Learning Loop
The seventh component is what turns a one-time project into an ongoing capability: a regular rhythm of review and a mechanism for feeding what you learn back into the system.
Cadence means a standing review – monthly, in most cases – where the team examines production signals: quality trends, cost trends, escalation patterns, incidents, and user behavior. This is an operating review, like the ones finance runs on cost centers or operations runs on production lines.
The learning loop means those signals actually change something. Evaluation test sets get updated to reflect new edge cases. Routing rules get refined based on escalation patterns. Risk boundaries get adjusted based on incident data. And, critically, lessons from one initiative inform the next one. The organization builds a portfolio-level understanding of which workflows respond well to AI, which data patterns create recurring friction, and which integration approaches lead to durable outcomes. This includes evolving how context is engineered into AI systems – an increasingly vital discipline we explore in our guide to AI context engineering.
This is how AI maturity compounds: through operational learning that accumulates and gets reused.
How to Build AI That Works at Scale
The seven components above are the structure. This section is the build sequence – how you actually get from “we should do this” to a functioning operating model inside a real organization with existing politics, budgets, and priorities.
Start with One Workflow
Do not start with an AI strategy. Start with one workflow where the manual effort is visible, the cost of delay is real, and the unit of work is countable. Onboarding review. Invoice exceptions. Field inspections. Contact center triage. Internal knowledge search. Pick the one where the pain is obvious, and the measurement is straightforward.
Map that workflow in plain language: what triggers it, where the decision points are, what data gets touched, where the handoffs happen, what fails today, and what the current service levels look like. This map becomes the anchor for everything that follows. It prevents the conversation from drifting into abstract AI strategy and keeps it grounded in how work actually gets done.
Fill In the Decision Rights Before You Design Anything
Name the four owners for this specific workflow. Write down the decisions that belong to each one. What gets automated and what stays human. What data can the system retrieve and store? What error rates are acceptable? What triggers a rollback?
Do this before any technical design begins. Teams that skip this step build for an imagined boundary and discover the real one during deployment, which is expensive, demoralizing, and slow. Teams that do this step first design within the boundary that will actually get approved. The result is less rework, faster reviews, and fewer surprises.
Model the Economics Before You Build
Estimate the cost per unit of work in the current process – fully loaded, including human time, rework, and the cost of errors. Then estimate what that cost looks like with the AI system in place, including inference, retrieval, human review for escalations, monitoring, and overhead.
If the economics do not work on paper, they will not work in production. Kill it early and move to the next candidate. If the economics are strong, you now have a funding case that finance can evaluate, not an AI pitch that needs faith.
Build the Pilot as a Mini Production Stack
The old approach to pilots was to build a quick demo and worry about production later. The problem is that “later” never comes cleanly. The demo succeeds, leadership expects production, and the team discovers that none of the production requirements – access controls, evaluation, monitoring, compliance logging – were designed in.
Build pilots like small production systems from the start. Private endpoints. Access controls wired to real enterprise roles. An evaluation harness that tests quality, safety, and cost against the actual workflow. Monitoring that detects drift. Logging that satisfies compliance. This is the approach Sombra takes across all generative AI development engagements – production-grade from day one.
This changes the incentive structure. Teams ship fewer pilots, but the pilots they ship are real. When a pilot built this way succeeds, the path to production is a scaling decision.

Write the Scale and Stop Criteria Before Launch
Before the pilot goes live, write down what success looks like and what failure looks like, in operational terms that the business owner and risk owner can evaluate. Attach each criterion to a named owner and a review cadence.
This single practice eliminates most of the political ambiguity that kills AI initiatives. When the criteria are written down, the review meeting is about evidence. When they are not, the meeting is about opinions, and opinions are subject to organizational gravity: the loudest voice, the most senior stakeholder, the most recent incident.
Why Partner-Led AI Operating Models Succeed More Often
Everything above, of course, is doable internally. The question is whether your organization will actually do it, given the other demands on the same people’s time, the political dynamics around data, and the simple fact that operating model design is a cross-disciplinary skill that most teams are building for the first time.
The MIT NANDA study mentioned that vendor-led, workflow-integrated AI projects succeed about twice as often as internal builds. That gap is about three things that experienced partners bring to the table.
Pattern Recognition
When a team builds its first AI operating model, every lesson must be learned from the ground up. An experienced partner, having worked across various industries and company sizes, brings valuable pattern recognition. They understand which workflows are suited to AI and which, despite appearing promising, hide unexpected complexities. They can anticipate when data boundary issues are likely to arise and distinguish escalation designs that perform well in production from those that only work in theory.
In our AI Lab, we have seen this pattern recognition change outcomes repeatedly. A global construction company was spending significant time on an internal search that returned incomplete results. An accessibility company was hitting the limits of rule-based detection. An LPG distributor was drowning in manual safety reviews. In each case, the first and most important work was not building the AI system. It was understanding the workflow deeply enough to define the right unit of work, the right boundaries, and the right escalation design. That understanding comes from experience.
Structured Decision-Making
The biggest value of a canvas-based operating model approach is that it forces hard conversations early. Who owns this? What can the system touch? What error rate is acceptable?
Internal teams often struggle with these conversations. The business owner does not want to name an acceptable error rate because it creates accountability. The data owner does not want to define boundaries because it limits future flexibility. The platform owner does not want to commit to monitoring because it is not glamorous.
A partner creates a forcing function. The canvas session happens because an external engagement has a timeline and deliverables. The hard questions get answered because the partner’s process requires answers. Think of it like the hint of how organizations make uncomfortable decisions.
Honest Economics
Partners who have done this before are willing to tell you that your favorite idea has weak unit economics. Internal teams often cannot do this because they are navigating the same organizational incentives that created the idea in the first place.
In our impact analysis work, we regularly find that the initiative leadership is most excited about is not the one with the strongest economic case. Sometimes a less visible workflow has dramatically better returns because the volume is higher, the manual cost is clearer, or the data is more accessible. A partner can surface that finding without career risk.
We have identified cost-saving opportunities up to $2M annually through feasibility validation, and we have also killed ideas that sounded good but would have consumed budget without producing proportional results. Both outcomes are valuable. The second one is the one internal teams find hardest to deliver.

How Sombra AI Lab Does This
We help enterprises define what to build before the engineering starts, then move validated initiatives into delivery with clear ownership, scope, and success criteria.
The engagement follows the operating model logic described above. We start with workshops that map real workflows and fill in the canvas – unit of work, decision owners, data boundaries, risk design. We conduct independent research to identify where AI creates measurable value, assessed through a Level of Effort lens that covers scope, complexity, data readiness, and organizational dependencies.
We model impact, including cost reduction, throughput, and revenue – and we model effort, so that leadership sees the full tradeoff. We produce architecture proposals with rationale, expected ROI, delivery path, assumptions, and measurable success criteria.
The result is a portfolio of initiatives that are feasible, aligned, and execution ready – a set of validated bets with clear operating models around each one.
If you want to start, pick one workflow. Run the canvas. Name the owners. Model the economics. Write the criteria. That is more operating model work than most companies have done across their entire AI portfolio. And if you want help doing it, that is what we built the AI Lab to do.








